概述
在java开发中,序列化是一种机制,用来将一个对象转换成一个字节流,反序列化刚好是一个反向的过程,它是基于字节流在内存中重新构建出一个实际的java对象,这种机制经常被用来持久化对象
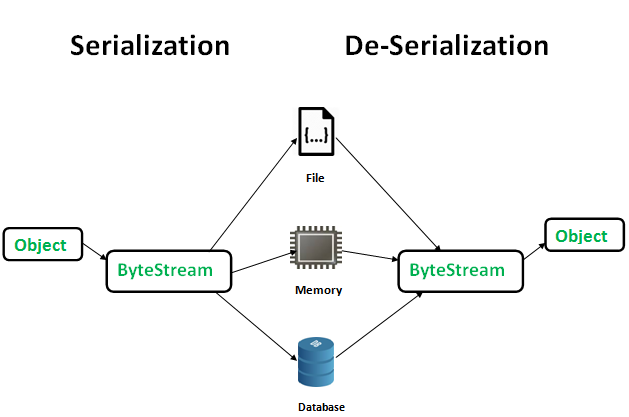
字节流的创建是不依赖于平台,因此对象的序列化和反序列化也是不依赖于平台的。
实际开发中,想要序列化一个对象,必须实现java.io.Serializable接口。通常情况下,只需要简单的实现的这个接口(这个接口没有任何方法需要实现类来实现)就够了,但是如果有一些特殊的处理,就需要实现以下方法:
private void writeObject(java.io.ObjectOutputStream out) throws IOException
private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException;- writeObject的职责是保存序列化对象的状态以便于在反序列化时能够重建它,当你没有重写这个方法时,它默认会调用ObjectOutputStream中的defaultWriteObject方法来保存对象的状态,这个方法会忽略父类或子类里的字段,自身的静态字段和transient的字段也会被忽略。
- readObject的职责刚好和write相反,同样在没有重写这个方法时,它也会调用ObjectInputStream中的defaultReadObject方法来重建对象,同样的会忽略静态和transient的字段
实际应用场景
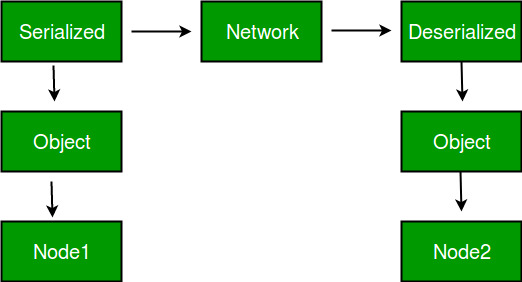 通过对象需要网络传输时,这里网络传输,泛指RPC调用或消息处理,一般需要把对象序列化,然后接收端再反序列化
通过对象需要网络传输时,这里网络传输,泛指RPC调用或消息处理,一般需要把对象序列化,然后接收端再反序列化
要记住的知识点
- 如果父类已经实现了Serializable接口,那么子类就不需要实现了
- 非静态和非transient的字段才能够序列化和反序列化
- 反序列化时是不会调用类的构造函数
- 被引用的类也必须要实现Serializable接口
SerialVersionUID
- 序列化运行时会为每一个实现了序列化接口的类附加一个版本号 ,叫做SerialVersionUID,它是用来在反序列化时,校验发送者和序列化对象的接收者加载的class是否和序列化时是一致的,如果接收者通过序列化的对象来重建一个对象时,发现这个版本和发送者的不一致,那么反序列化将会抛出InvalidClassException,通常每个序列化类要显示的定义这个字段, 它必须是static, final且类型一定是long
- 尽管jvm会在运行时动态为每个实现了Serializable接口的类生成一个SerialVersionUID,但是还是推荐大家显示定义一个这样的字段,为什么这么说呢,因为默认的versionId太过于依赖于编译器的实现,因此可能会在反序列化产生一些未预期的问题,为了保证跨不同编译器实现的版本号值的一致性,强烈推荐大家显式的定义这个字段并赋值,同时将这个字段设置为private